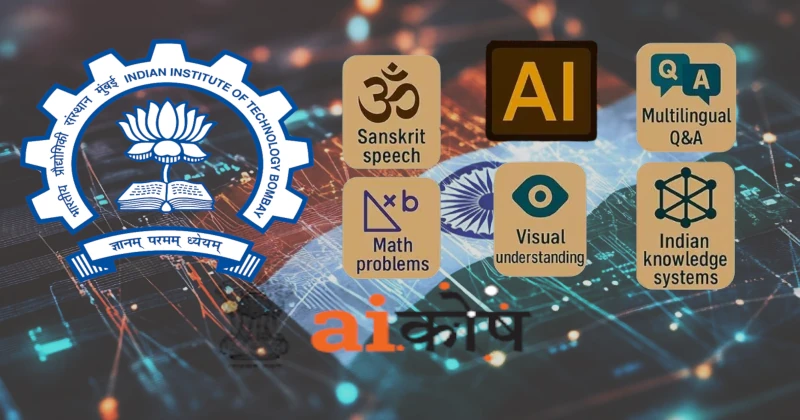
IIT Bombay has released 16 culturally significant and diverse AI datasets on AIKOSH, the Government of India’s official AI repository, developed under the aegis of the Ministry of Electronics and Information Technology (MeitY).
A Bharat-Centric AI Push: “AI by India, for India”
This initiative isn’t just about data—it’s about asserting India’s AI sovereignty in a world dominated by western-centric datasets. The 16 datasets released by IIT Bombay reflect India’s unique diversity, with a sharp focus on language, script, document processing, and multimodal understanding.
Key components of the release include:
- Handwritten and printed Indian scripts: Enabling advanced OCR and NLP for native languages.
- Scanned table data from Indian documents: Facilitating document digitisation and automation for governance and legal sectors.
- Multilingual Indian audio datasets: Enhancing speech recognition and synthesis systems for underserved languages.
- Drone surveillance imagery: Boosting AI capabilities in smart agriculture, disaster management, and border surveillance.
- Visual Question-Answering (VQA) datasets contextualised for India: Enabling intelligent systems that understand Indian imagery and cultural cues.
This initiative is being hailed as a pivotal step towards responsible and contextual AI development, essential for unlocking the true potential of technology in Indian ecosystems—from rural Bharat to high-tech urban centers.
AIKOSH: India’s secure data arsenal for the future
AIKOSH is India’s first-of-its-kind AI repository—a digital fort of datasets, pre-trained models, toolkits, and real-world use cases. Envisioned as a self-reliant ecosystem to fuel AI research and innovation, the platform empowers Indian developers, researchers, startups, and institutions to build solutions tailored for Indian realities.
With this release, IIT Bombay emerges as a trailblaser in aligning academic R&D with national AI priorities, contributing not just to data availability but also to the ethics and accountability of AI development in India.
AI systems are only as inclusive and intelligent as the data they are trained on. Until now, much of the global AI landscape has been trained on western-centric datasets, often neglecting non-English languages, diverse scripts, and culturally specific content. India, with its 122+ major languages, diverse scripts, and multilingual populations, cannot afford to remain dependent on such skewed data foundations.
The datasets released today represent a reclamation of India’s data identity, empowering researchers to:
- Train models that understand regional languages like Marathi, Tamil, Assamese, Bhojpuri, Sanskrit, and more.
- Solve local problems—from automatic processing of handwritten Indian forms to speech interfaces for rural populations.
- Build inclusive AI models that reflect and serve India’s socio-cultural realities, not just borrowed global paradigms.
This move is part of a broader national vision to make India a global leader in responsible AI, with a strong focus on open data, transparency, and indigenous development. With IIT Bombay’s contribution, AIKOSH now grows into a powerhouse of innovation, signaling to the world that India is not just catching up—it is leading the AI transformation with its own voice, data, and values.
The released datasets and tools can be accessed by researchers, developers, students, startups, and government institutions at aikosh.indiaai.gov.in. The initiative also aligns with MeitY’s broader mission of Digital India, Make in AI, and Bharat Gen, aimed at democratising access to AI technologies and resources across all sectors.
With this release, IIT Bombay isn’t just powering AI innovation—it’s scripting a new digital future for Bharat. A future where AI speaks our languages, sees through our lenses, and solves problems rooted in our soil.